Profiling Using HDF5 User Guide
Contents
OverviewAdministration
Profiling Jobs
HDF5
Data Structure
Overview
The acct_gather_profile/hdf5 plugin allows Slurm to coordinate collecting
data on jobs it runs on a cluster that is more detailed than is practical to
include in its database.
acct_gather_profile / hdf5プラグインを使用すると、Slurmは、データベースに含めるのが実際的であるよりも詳細な、クラスター上で実行されるジョブに関するデータの収集を調整できます。
The data comes from periodically sampling various
performance data either collected by Slurm, the operating system, or
component software.
データは、Slurm、オペレーティングシステム、またはコンポーネントソフトウェアによって収集されたさまざまなパフォーマンスデータを定期的にサンプリングして取得されます。
The plugin will record the data from each source
as a Time Series and also accumulate totals for each statistic for
the job.
プラグインは、各ソースからのデータを時系列として記録し、ジョブの各統計の合計も累積します。
Time Series are energy data collected by an acct_gather_energy plugin,
I/O data from a network interface collected by an acct_gather_interconnect
plugin, I/O data from parallel file systems such as Lustre collected by an
acct_gather_filesystem plugin, and task performance data such as local disk I/O,
cpu consumption, and memory use from a jobacct_gather plugin.
時系列は、acct_gather_energyプラグインによって収集されたエネルギーデータ、acct_gather_interconnectプラグインによって収集されたネットワークインターフェイスからのI / Oデータ、acct_gather_filesystemプラグインによって収集されたLustreなどの並列ファイルシステムからのI / Oデータ、およびローカルディスクなどのタスクパフォーマンスデータです。 jobacct_gatherプラグインからのI / O、cpu消費、およびメモリ使用。
Data from other sources may be added in the future.
他のソースからのデータは将来追加される可能性があります。
The data is collected into a file on a shared file system for each step on
each allocated node of a job and then merged into an HDF5 file.
データは、ジョブの割り当てられたノードごとに、共有ファイルシステム上のファイルに収集され、HDF5ファイルにマージされます。
Individual files on a shared file system was chosen because it is possible
that the data is voluminous so solutions that pass data to the Slurm control
daemon via RPC may not scale to very large clusters or jobs with
many allocated nodes.
共有ファイルシステム上の個々のファイルが選択されたのは、データが大量である可能性があるため、RPCを介してSlurm制御デーモンにデータを渡すソリューションが非常に大きなクラスターやノードが割り当てられたジョブに拡張できない可能性があるためです。
A separate
Slurm Profile Accounting Plugin API (AcctGatherProfileType) documents how
to write other Profile Accounting plugins.
別のSlurmプロファイルアカウンティングプラグインAPI(AcctGatherProfileType)には、他のプロファイルアカウンティングプラグインの作成方法が記載されています。
Administration
Shared File System
The HDF5 Profile Plugin requires a common shared file system on all
the compute nodes.
HDF5プロファイルプラグインには、すべての計算ノードに共通の共有ファイルシステムが必要です。
While a job is running, the plugin writes a
file into this file system for each step of the job on each node.
ジョブの実行中、プラグインは各ノードのジョブの各ステップでこのファイルシステムにファイルを書き込みます。
When
the job ends, the merge process is launched and the node-step files
are combined into one HDF5 file for the job.
ジョブが終了すると、マージプロセスが開始され、ノードステップファイルがジョブの1つのHDF5ファイルに結合されます。
The root of the directory structure is declared in the ProfileHDF5Dir
option in the acct_gather.conf file.
ディレクトリ構造のルートは、acct_gather.confファイルのProfileHDF5Dirオプションで宣言されています。
The directory will be created by
Slurm if it doesn't exist.
ディレクトリが存在しない場合は、Slurmによって作成されます。
Each user will have
their own directory created in the ProfileHDF5Dir which contains
the HDF5 files.
各ユーザーは、HDF5ファイルを含むProfileHDF5Dirに独自のディレクトリを作成します。
All the directories and files are created by the
SlurmdUser which is usually root.
すべてのディレクトリとファイルは、通常はルートであるSlurmdUserによって作成されます。
The user specific directories, as well
as the files inside, are chowned to the user running the job so they
can access the files.
ユーザー固有のディレクトリとその中のファイルは、ジョブを実行しているユーザーがファイルにアクセスできるように変更されます。
Since user root is usually creating these
files/directories a root squashed file system will not work for
the ProfileHDF5Dir.
ユーザーrootは通常これらのファイル/ディレクトリを作成しているため、rootが押しつぶされたファイルシステムはProfileHDF5Dirでは機能しません。
Each user that creates a profile will have a subdirectory in the profile
directory that has read/write permission only for the user.
プロファイルを作成する各ユーザーは、プロファイルディレクトリに、そのユーザーに対してのみ読み取り/書き込み権限を持つサブディレクトリを持ちます。
Configuration parameters
The profile plugin is enabled in the
slurm.conf file and it is internally
configured in the
acct_gather.conf file.
プロファイルプラグインはslurm.confファイルで有効になっており、acct_gather.confファイルで内部的に構成されています。
slurm.conf parameters
これにより、HDF5プラグインが有効になります。
AcctGatherProfileType = acct_gather_profile/hdf5
This sets the sampling frequency for data types:これにより、データ型のサンプリング頻度が設定されます。
JobAcctGatherFrequency = <seconds>
acct_gather.conf parameters
These parameters are directly used by the HDF5 Profile Plugin.
これらのパラメータは、HDF5プロファイルプラグインによって直接使用されます。
- ProfileHDF5Dir = <path>
- ProfileHDF5Default = [options]
This parameter is the path to the shared folder into which the
acct_gather_profile plugin will write detailed data as an HDF5 file.
このパラメーターは、acct_gather_profileプラグインが詳細データをHDF5ファイルとして書き込む共有フォルダーへのパスです。
The directory is assumed to be on a file system shared by the controller and
all compute nodes.
ディレクトリは、コントローラとすべての計算ノードによって共有されるファイルシステム上にあると想定されています。
This is a required parameter.
これは必須パラメーターです。
A comma delimited list of data types to be collected for each job submission.
ジョブの送信ごとに収集されるデータ型のコンマ区切りのリスト。
Use this option with caution.
このオプションは注意して使用してください。
A node-step file will be created on every
node for every step of every job.
ノードステップファイルは、すべてのジョブのすべてのステップのすべてのノードに作成されます。
They will not automatically be merged
into job files.
それらはジョブファイルに自動的にマージされません。
(Even job files for large numbers of small jobs would fill the
file system.)
(多数の小さなジョブのジョブファイルでさえ、ファイルシステムを埋め尽くします。)
This option is intended for test environments where you
might want to profile a series of jobs but do not want to have to
add the --profile option to the launch scripts.
このオプションは、一連のジョブのプロファイルを作成したいが、起動スクリプトに--profileオプションを追加する必要がないテスト環境を対象としています。
The options are described below and in the man pages for acct_gather.conf,
srun, salloc and sbatch commands.
オプションについては、以下およびacct_gather.conf、srun、salloc、およびsbatchコマンドのマニュアルページで説明しています。
Time Series Control Parameters
Other plugins add time series data to the HDF5 collection.
他のプラグインは、HDF5コレクションに時系列データを追加します。
They typically
have a default polling frequency specified in slurm.conf in the
JobAcctGatherFrequency parameter.
これらには通常、JobAcctGatherFrequencyパラメーターのslurm.confで指定されたデフォルトのポーリング頻度があります。
The polling frequency can be overridden
using the --acctg-freq
srun parameter.
ポーリング頻度は、-acctg-freqsrunパラメーターを使用してオーバーライドできます。
They are both of the form task=sec,energy=sec,filesystem=sec,network=sec.
これらは両方ともtask = sec、energy = sec、filesystem = sec、network = secの形式です。
The IPMI energy plugin also needs the EnergyIPMIFrequency value set
in the acct_gather.conf file.
IPMIエネルギープラグインには、acct_gather.confファイルで設定されたEnergyIPMIFrequency値も必要です。
This sets the rate at which the plugin samples
the external sensors.
これにより、プラグインが外部センサーをサンプリングする速度が設定されます。
This value should be the same as the energy=sec in
either JobAcctGatherFrequency or --acctg-freq.
この値は、JobAcctGatherFrequencyまたは--acctg-freqのいずれかのenergy = secと同じである必要があります。
Note that the IPMI and profile sampling are not synchronous.
IPMIとプロファイルのサンプリングは同期していないことに注意してください。
The profile sample simply takes the last available IPMI sample value.
プロファイルサンプルは、利用可能な最後のIPMIサンプル値を取得するだけです。
If the profile energy sample is more frequent than the IPMI sample rate,
the IPMI value will be repeated.
プロファイルエネルギーサンプルがIPMIサンプルレートよりも頻繁である場合、IPMI値が繰り返されます。
If the profile energy sample is greater
than the IPMI rate, IPMI values will be lost.
プロファイルエネルギーサンプルがIPMIレートよりも大きい場合、IPMI値は失われます。
Also note that smallest effective IPMI (EnergyIPMIFrequency) sample rate
for 2013 era Intel processors is 3 seconds.
また、2013年のIntelプロセッサの最小有効IPMI(EnergyIPMIFrequency)サンプルレートは3秒であることに注意してください。
Profiling Jobs
Data Collection
The --profile option on salloc|sbatch|srun controls whether data is
collected and what type of data is collected.
salloc | sbatch | srunの--profileオプションは、データを収集するかどうか、および収集するデータのタイプを制御します。
If --profile is not specified
no data collected unless the ProfileHDF5Default
option is used in acct_gather.conf. --profile on the command line overrides
any value specified in the configuration file.
--profileが指定されていない場合、acct_gather.confでProfileHDF5Defaultオプションが使用されていない限り、データは収集されません。コマンドラインの--profileは、構成ファイルで指定された値を上書きします。
enables detailed data collection by the acct_gather_profile plugin.
acct_gather_profileプラグインによる詳細なデータ収集を有効にします。
Detailed data are typically time-series that are stored in a HDF5 file for
the job.
詳細データは通常、ジョブのHDF5ファイルに保存される時系列です。
- All
- All data types are collected.
すべてのデータ型が収集されます。
(Cannot be combined with other values.)
(他の値と組み合わせることはできません。)
- None
- No data types are collected.
データ型は収集されません。
This is the default.
これがデフォルトです。
(Cannot be combined with other values.)
(他の値と組み合わせることはできません。)
- Energy
- Energy data is collected.
エネルギーデータが収集されます。 - Filesystem
- Filesystem data is collected.
ファイルシステムデータが収集されます。
Currently only Lustre filesystem is supported.
現在、Lustreファイルシステムのみがサポートされています。 - Network
- Network (InfiniBand) data is collected.
ネットワーク(InfiniBand)データが収集されます。 - Task
- Task (I/O, Memory, ...) data is collected.
タスク(I / O、メモリなど)のデータが収集されます。
Data Consolidation
The node-step files are merged into one HDF5 file for the job using the
sh5util.
ノードステップファイルは、sh5utilを使用してジョブ用に1つのHDF5ファイルにマージされます。
If the job is started with sbatch, the command line may added to the normal
launch script, For example:
ジョブがsbatchで開始された場合、コマンドラインが通常の起動スクリプトに追加されることがあります。次に例を示します。
sbatch -n1 -d$SLURM_JOB_ID --wrap="sh5util -j $SLURM_JOB_ID"
Data Extraction
The sh5util program can also be used to extract
specific data from the HDF5 file and write it in comma separated value (csv)
form for importation into other analysis tools such as spreadsheets.
sh5utilプログラムを使用して、HDF5ファイルから特定のデータを抽出し、それをコンマ区切り値(csv)形式で書き込んで、スプレッドシートなどの他の分析ツールにインポートすることもできます。
HDF5
HDF5 is a well known structured data set that allows heterogeneous but
related data to be stored in one file.
HDF5はよく知られている構造化データセットであり、異種であるが関連するデータを1つのファイルに保存できます。
(.i.e. sections for energy statistics, network I/O, Task data, etc.)
(つまり、エネルギー統計、ネットワークI / O、タスクデータなどのセクション)
Its internal structure resembles a
file system with groups being similar to directories and
data sets being similar to files.
その内部構造はファイルシステムに似ており、グループはディレクトリに似ており、データセットはファイルに似ています。
It also allows attributes
to be attached to groups to store application defined properties.
また、属性をグループにアタッチして、アプリケーションで定義されたプロパティを格納することもできます。
There are commodity programs, notably
HDFView, for viewing and manipulating these files.
これらのファイルを表示および操作するためのコモディティプログラム、特にHDFViewがあります。
Below is a screen shot from HDFView expanding the job tree and showing the
attributes for a specific task.
以下は、ジョブツリーを展開し、特定のタスクの属性を示すHDFViewのスクリーンショットです。
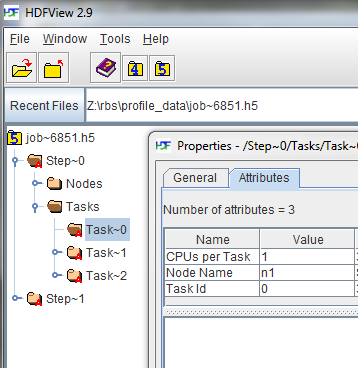
Data Structure
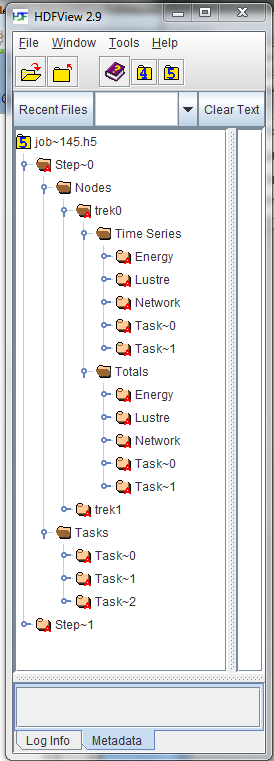 |
In the job file, there will be a group for each step of the job.
|
Energy Data
AcctGatherEnergyType=acct_gather_energy/ipmi
is required in slurm.conf to collect energy data.
エネルギーデータを収集するには、slurm.confにAcctGatherEnergyType = acct_gather_energy / ipmiが必要です。
Appropriately set energy=freq in either JobAcctGatherFrequency in slurm.conf
or in --acctg-freq on the command line.
slurm.confのJobAcctGatherFrequencyまたはコマンドラインの--acctg-freqのいずれかでenergy = freqを適切に設定します。
Also appropriately set EnergyIPMIFrequency in acct_gather.conf.
また、acct_gather.confでEnergyIPMIFrequencyを適切に設定します。
Each data sample in the Energe Time Series contains the following data items.
Energe Time Seriesの各データサンプルには、次のデータ項目が含まれています。
- Date Time
- Time of day at which the data sample was taken.
データサンプルが取得された時刻。
This can be used to correlate activity with other sources such as logs.
これは、アクティビティをログなどの他のソースと関連付けるために使用できます。 - Time
- Elapsed time since the beginning of the step.
ステップの開始からの経過時間。 - Power
- Power consumption during the interval.
インターバル中の消費電力。 - CPU Frequency
- CPU Frequency at time of sample in kilohertz.
サンプル時のCPU周波数(キロヘルツ)。
Filesystem Data
AcctGatherFilesystemType=acct_gather_filesystem/lustre
is required in slurm.conf to collect task data.
タスクデータを収集するには、slurm.confにAcctGatherFilesystemType = acct_gather_filesystem / lustreが必要です。
Appropriately set Filesystem=freq in either JobAcctGatherFrequency in slurm.conf
or in --acctg-freq on the command line.
slurm.confのJobAcctGatherFrequencyまたはコマンドラインの--acctg-freqのいずれかでFilesystem = freqを適切に設定します。
Each data sample in the Filesystem Time Series contains the following data items.
ファイルシステム時系列の各データサンプルには、次のデータ項目が含まれています。
- Date Time
- Time of day at which the data sample was taken.
データサンプルが取得された時刻。
This can be used to correlate activity with other sources such as logs.
これは、アクティビティをログなどの他のソースと関連付けるために使用できます。 - Time
- Elapsed time since the beginning of the step.
ステップの開始からの経過時間。 - Reads
- Number of read operations.
読み取り操作の数。 - Megabytes Read
- Number of megabytes read.
読み取られたメガバイト数。 - Writes
- Number of write operations.
書き込み操作の数。 - Megabytes Write
- Number of megabytes written.
書き込まれたメガバイト数。
Network (Infiniband Data)
JobAcctInfinibandType=acct_gather_interconnect/ofed
is required in slurm.conf to collect task data.
タスクデータを収集するには、slurm.confでJobAcctInfinibandType = acct_gather_interconnect / ofedが必要です。
Appropriately set network=freq in either JobAcctGatherFrequency in slurm.conf
or in --acctg-freq on the command line.
slurm.confのJobAcctGatherFrequencyまたはコマンドラインの--acctg-freqのいずれかでnetwork = freqを適切に設定します。
Each data sample in the Network Time Series contains the following
data items.
ネットワーク時系列の各データサンプルには、次のデータ項目が含まれています。
- Date Time
- Time of day at which the data sample was taken.
データサンプルが取得された時刻。
This can be used to correlate activity with other sources such as logs.
これは、アクティビティをログなどの他のソースと関連付けるために使用できます。 - Time
- Elapsed time since the beginning of the step.
ステップの開始からの経過時間。 - Packets In
- Number of packets coming in.
入ってくるパケットの数。 - Megabytes Read
- Number of megabytes coming in through the interface.
インターフェイスを介して入力されるメガバイト数。 - Packets Out
- Number of packets going out.
送信されるパケットの数。 - Megabytes Write
- Number of megabytes going out through the interface.
インターフェイスを介して送信されるメガバイト数。
Task Data
JobAcctGatherType=jobacct_gather/linux
is required in slurm.conf to collect task data.
タスクデータを収集するには、slurm.confにJobAcctGatherType = jobacct_gather / linuxが必要です。
Appropriately set task=freq in either JobAcctGatherFrequency in slurm.conf
or in --acctg-freq on the command line.
slurm.confのJobAcctGatherFrequencyまたはコマンドラインの--acctg-freqのいずれかでtask = freqを適切に設定します。
Each data sample in the Task Time Series contains the following data
items.
タスク時系列の各データサンプルには、次のデータ項目が含まれています。
- Date Time
- Time of day at which the data sample was taken.
データサンプルが取得された時刻。
This can be used to correlate activity with other sources such as logs.
これは、アクティビティをログなどの他のソースと関連付けるために使用できます。 - Time
- Elapsed time since the beginning of the step.
ステップの開始からの経過時間。 - CPU Frequency
- CPU Frequency at time of sample.
サンプル時のCPU周波数。 - CPU Time
- Seconds of CPU time used during the sample.
サンプル中に使用されたCPU時間の秒数。 - CPU Utilization
- CPU Utilization during the interval.
インターバル中のCPU使用率。 - RSS
- Value of RSS at time of sample.
サンプル時のRSSの値。 - VM Size
- Value of VM Size at time of sample.
サンプル時のVMサイズの値。 - Pages
- Pages used in sample.
サンプルで使用されているページ。 - Read Megabytes
- Number of megabytes read from local disk.
ローカルディスクから読み取られたメガバイト数。 - Write Megabytes
- Number of megabytes written to local disk.
ローカルディスクに書き込まれたメガバイト数。
Last modified 30 January 2020