Failure Management Support
Overview
Modern high performance computers can include thousands of nodes and
millions of cores.
最新の高性能コンピューターには、数千のノードと数百万のコアを含めることができます。
The shear number of components can result in a mean time between failure
measured in hours, which is lower than the execution time of many applications.
コンポーネントのせん断数により、平均故障間隔が時間単位で測定される可能性があります。これは、多くのアプリケーションの実行時間よりも短くなります。
In order to effectively manage such large systems, Slurm includes infrastructure
designed to work with applications allowing them to manage failures and keep
running.
このような大規模なシステムを効果的に管理するために、Slurmには、アプリケーションと連携して障害を管理し、実行を継続できるように設計されたインフラストラクチャが含まれています。
Slurm infrastructure includes support for:
Slurmインフラストラクチャには、以下のサポートが含まれます。
- Permitting users to drain nodes they believe are failing
失敗していると思われるノードをドレインすることをユーザーに許可する - A pool of hot-spare resources, which applications can use to replace
failed or failing resources in their current allocation
ホットスペアリソースのプール。アプリケーションは、現在の割り当てで失敗したリソースまたは失敗したリソースを置き換えるために使用できます。 - Extending a job's time limit to recover from failures
障害から回復するためにジョブの制限時間を延長する - Real time application notification of failures and availability of
replacement resources
障害と交換用リソースの可用性に関するリアルタイムのアプリケーション通知 - Access control list control over failure management capabilities
障害管理機能に対するアクセス制御リストの制御 - A library that applications can link to directly without contamination
by GPL licensing
アプリケーションがGPLライセンスによる汚染なしに直接リンクできるライブラリ - A command line interface to these capabilities
これらの機能へのコマンドラインインターフェイス
Architecture
The failure management is implemented as a client server in which the
server is a plugin in slurmctld and the client is an API
that negotiate the resource management allocation from an already running job.
障害管理は、サーバーがslurmctldのプラグインであり、クライアントがすでに実行中のジョブからのリソース管理割り当てをネゴシエートするAPIであるクライアントサーバーとして実装されます。
These are the architectural components:
これらはアーキテクチャコンポーネントです。
-
The plugin implements the server logic which keeps track of nodes allocated
to jobs and job steps, the state of nodes and their availability.
プラグインは、ジョブとジョブステップに割り当てられたノード、ノードの状態、およびそれらの可用性を追跡するサーバーロジックを実装します。
Having the complete view of resource allocations the server can effectively help applications to be resilient to node failures.
サーバーは、リソース割り当ての完全なビューを持っているため、アプリケーションがノード障害に対して回復力を持つのに効果的に役立ちます。
- libsmd.so, libsmd.a and smd.h are the client interface
and library to the non stop services based on a jobID.
libsmd.so、libsmd.a、およびsmd.hは、jobIDに基づくノンストップサービスへのクライアントインターフェイスおよびライブラリです。
-
smd command build on top of the library provides command line interface
to failure management services.
ライブラリ上に構築されたsmdコマンドは、障害管理サービスへのコマンドラインインターフェイスを提供します。
nonstop.sh shell script which automates the node replacement based on user supplied environment variables.
ユーザー指定の環境変数に基づいてノードの置換を自動化するnonstop.shシェルスクリプト。
The controller keeps nodes in several states which reflects their usability.
コントローラは、ノードの使いやすさを反映するいくつかの状態をノードに保持します。
- Failed hosts, currently out of service.
障害が発生したホスト、現在サービスを停止しています。
- Failing hosts, malfunctioning and/or expected to fail.
障害のあるホスト、誤動作、および/または障害が予想されます。
- Hot Spare.
ホットスペア。
A cluster-wide pool of resources to be made available to jobs with failed/failing nodes.
障害が発生した/障害が発生したノードを持つジョブで使用できるようにする、クラスター全体のリソースのプール。
The hot spare pool can be partition based, the administrator specifies how many spares in a given partition.
ホットスペアプールはパーティションベースにすることができ、管理者は特定のパーティション内のスペアの数を指定します。
Failing hosts can be drained and then dropped from the allocation, giving application
flexibility to manage its own resources
障害が発生したホストを排出してから割り当てから削除できるため、アプリケーションは独自のリソースを柔軟に管理できます。
Drained nodes can be put back on-line by the administrator and they will go
automatically back to the spare pool.
排出されたノードは、管理者がオンラインに戻すことができ、自動的にスペアプールに戻ります。
Failed nodes can be put back on-line and
they will go automatically back to the spare pool.
障害が発生したノードはオンラインに戻すことができ、スペアプールに自動的に戻ります。
Application usually detects the failure by itself when losing one or more of its
component, then it is able to notify Slurm of failures and drain nodes.
アプリケーションは通常、1つ以上のコンポーネントが失われたときにそれ自体で障害を検出し、Slurmに障害を通知してノードをドレインすることができます。
Application can also query Slurm about state of nodes in its allocation and/or
asks Slurm to replace its failed/failing nodes, then it can
アプリケーションは、割り当て内のノードの状態についてSlurmにクエリを実行したり、Slurmに障害のある/障害のあるノードを置き換えるように要求したりすることもできます。
- Wait for nodes become available, eventually increasing its runtime till
then
ノードが使用可能になるのを待ち、最終的にはそれまでランタイムを増やします
- Increase its runtime upon node replacement
ノード交換時にランタイムを増やす
- Drop the nodes and continue, eventually increasing its runtime
ノードを削除して続行し、最終的にランタイムを増やします
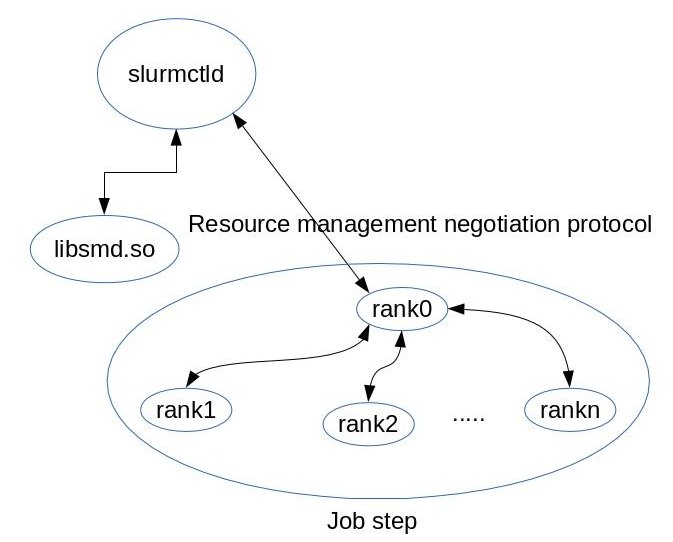
The figure 1 shows the component interaction.
図1は、コンポーネントの相互作用を示しています。
- The job step.
ジョブステップ。
Rank 0 is the rank responsible for monitoring the state of other ranks, it then negotiates with the controller resource allocation in case of failure.
ランク0は、他のランクの状態を監視する責任があるランクであり、障害が発生した場合はコントローラーのリソース割り当てとネゴシエートします。
There are two ways in which rank 0 interacts with the controller:
ランク0がコントローラーと相互作用する方法は2つあります。
- Using a command that detects failure and generates a new hostlist for the
application.
障害を検出し、アプリケーションの新しいホストリストを生成するコマンドを使用します。
- Link with the smd library and subscribe with the controller for events.
smdライブラリとリンクし、イベントのコントローラーでサブスクライブします。
- Using a command that detects failure and generates a new hostlist for the
application.
- The slurmctld process itself which loads the failure management plugin.
障害管理プラグインをロードするslurmctldプロセス自体。
- The failure management plugin itself.
障害管理プラグイン自体。
The plugin talks to the smd library over a tcp/ip connection.
プラグインは、tcp / ip接続を介してsmdライブラリと通信します。
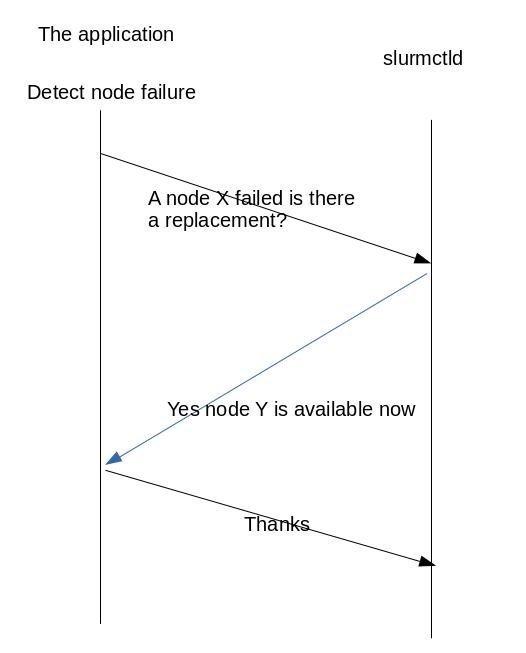
The figure 2 show a simple protocol interaction between the application and the controller.
図2は、アプリケーションとコントローラー間の単純なプロトコルの相互作用を示しています。
In this case the application detects the failure by itself so the job steps terminates.
この場合、アプリケーションはそれ自体で障害を検出するため、ジョブステップは終了します。
The application then asks for a node replacement either using the smd command with
appropriate parameters or via an API call.
次に、アプリケーションは、適切なパラメーターを指定したsmdコマンドを使用するか、API呼び出しを介して、ノードの置換を要求します。
In this specific example the controller allocates a new node to the application which can then initiates
a new job step.
この特定の例では、コントローラーは新しいノードをアプリケーションに割り当て、アプリケーションは新しいジョブステップを開始できます。
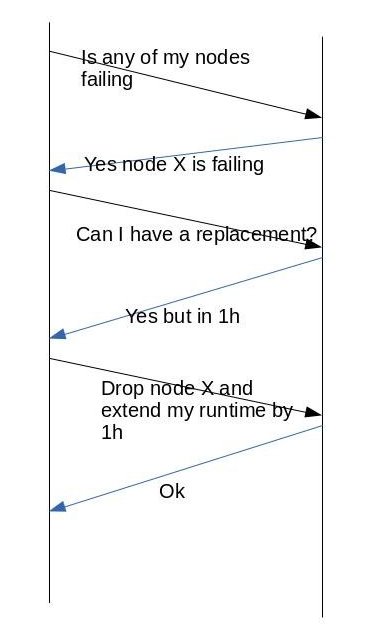
The figure 3 shows more complex protocol negotiation.
図3は、より複雑なプロトコルネゴシエーションを示しています。
In this case the application
query the controller to check if any node in the step has failed, then ask for replacement
which is available in 1 hour.
この場合、アプリケーションはコントローラーに照会して、ステップ内のいずれかのノードに障害が発生していないかどうかを確認してから、1時間以内に利用可能な交換を要求します。
The application then decides to drop the node and keep
running with less resources but having its runtime extended by 1 hour.
次に、アプリケーションはノードを削除し、より少ないリソースで実行を継続することを決定しますが、ランタイムは1時間延長されます。
Configuration
Slurm's slurmctld/nonstop plugin acts as the server for these
functions.
Slurmのslurmctld / nonstopプラグインは、これらの機能のサーバーとして機能します。
Configure in slurm.conf as follows:
slurm.confで次のように構成します。
SlurmctldPlugin=slurmctld/nonstop
This plugin uses a nonstop.conf file for it's configuration details.
このプラグインは、構成の詳細にnonstop.confファイルを使用します。
See "man nonstop.conf" for details about the options.
オプションの詳細については、「mannonstop.conf」を参照してください。
The nonstop.conf file must be in the same directory as your
slurm.conf file.
nonstop.confファイルは、slurm.confファイルと同じディレクトリにある必要があります。
A sample nonstop.conf file appears below.
サンプルのnonstop.confファイルを以下に示します。
# # Sample nonstop.conf file # # Same as BackupAddr in slurm.conf BackupAddr=bacco # Same as ControlAddr in slurm.conf ControlAddr=prometeo # Verbosity of plugin logging Debug=0 # Count of hot spare nodes in partition "batch" HotSpareCount=batch:8 # Maximum hot spare node use by any single job MaxSpareNodeCount=4 # Port the slurmctld/nonstop plugin reads from Port=9114 # Maximum time limit extension if no hot spares TimeLimitDelay=600 # Time limit extension for each replaced node TimeLimitExtend=2 # Users allowed to drain nodes UserDrainAllow=alan,brenda
An additional package named smd will also need to be installed.
smdという名前の追加パッケージもインストールする必要があります。
This package is available at no additional cost for systems under a support
contract with SchedMD LLC (including support contracts procured through other
vendors of Slurm support such as Bull and Cray).
このパッケージは、SchedMD LLCとのサポート契約(BullやCrayなどの他のSlurmサポートベンダーを通じて調達されたサポート契約を含む)に基づくシステムで追加費用なしで利用できます。
Please contact the appropriate vendor for the software.
ソフトウェアについては、適切なベンダーにお問い合わせください。
The smd package includes a library and command line interface,
libsmd and smd respectively.
smdパッケージには、ライブラリとコマンドラインインターフェイス、それぞれlibsmdとsmdが含まれています。
Note that libsmd is not under the GPL license and can be link by
other programs without those programs needing to be released under a
GPL license.
libsmdはGPLライセンスの下になく、GPLライセンスの下でリリースする必要のない他のプログラムによってリンクできることに注意してください。
Commands and API
In this paragraph we examine the user interaction with the system.
この段落では、システムとのユーザーの相互作用を調べます。
As stated previously users can use the smd command or the API.
前述のように、ユーザーはsmdコマンドまたはAPIを使用できます。
The smd command is driven by command line options, see smd man page for more
details.
smdコマンドは、コマンドラインオプションによって駆動されます。詳細については、smdのマニュアルページを参照してください。
However the smd command can also be driven by environment variables which makes it
easier to be deployed in user applications.
ただし、smdコマンドは環境変数によって駆動することもできるため、ユーザーアプリケーションへの展開が容易になります。
The environment variables describes what
action to take upon host failure or if the host is failing.
環境変数は、ホストに障害が発生した場合、またはホストに障害が発生した場合に実行するアクションを記述します。
The environmental variables to set are SMD_NONSTOP_FAILED or SMD_NONSTOP_FAILING they control the controller actions
when a node failed or it is failing.
設定する環境変数はSMD_NONSTOP_FAILEDまたはSMD_NONSTOP_FAILINGであり、ノードに障害が発生したとき、またはノードに障害が発生したときのコントローラーのアクションを制御します。
The variables can take the following values based on the desired action.
変数は、目的のアクションに基づいて次の値を取ることができます。
- REPLACE
Replace the failed/failing nodes.
障害が発生した/障害が発生したノードを交換します。
- DROP
Drop the nodes from the allocation.
割り当てからノードを削除します。
- TIME_LIMIT_DELAY=Xmin
If a job requires replacement resources and none are immediately available, then permit a job to extend its time limit by the length of time required to secure replacement resources up to the number of minutes specified.
ジョブに交換用リソースが必要で、すぐに使用できるものがない場合は、指定した分数まで交換用リソースを保護するために必要な時間だけ、ジョブの制限時間を延長することを許可します。
- TIME_LIMIT_EXTEND=Ymin
Specifies the number of minutes that a job can extend its time limit for each replaced node.
置き換えられたノードごとに、ジョブが制限時間を延長できる分数を指定します。
- TIME_LIMIT_DROP=Zmin
Specifies the number of minutes that a job can extend its time limit for each failed or failing node removed from the job's allocation.
ジョブの割り当てから削除された、失敗したノードまたは失敗したノードごとに、ジョブが制限時間を延長できる分数を指定します。
- EXIT_JOB
Exit the job upon node failure.
ノード障害時にジョブを終了します。
The variables can be combined in to logical and expressions.
変数は、論理式と式に組み合わせることができます。
- SMD_NONSTOP_FAILED="REPLACE:TIME_LIMIT_DELAY=4:EXIT_JOB
This directive instructs the smd command to attempt to replace failed/failing nodes, if replacement is not immediately available wait up to 4 minutes, then if still not available exit the job.
このディレクティブは、smdコマンドに、障害のある/障害のあるノードの置き換えを試みるように指示します。置き換えがすぐに利用できない場合は、最大4分待ってから、まだ利用できない場合はジョブを終了します。
- SMD_NONSTOP_FAILED="REPLACE:TIME_LIMIT_DELAY=4:DROP:TIME_LIMIT_DROP=10
This instructs smd command to attempt to replace nodes with a 4 minutes timeout, then drop the failed nodes and extend the step runtime by 10 minutes.
これにより、smdコマンドは、ノードを4分のタイムアウトで置き換えてから、障害が発生したノードを削除し、ステップの実行時間を10分延長するように指示します。
Example
In this use case analysis we illustrate how to use the nonstop.sh and steps.sh
script provided with the failure management package.
このユースケース分析では、障害管理パッケージで提供されるnonstop.shおよびsteps.shスクリプトの使用方法を示します。
The steps.sh is the Slurm batch script that executes job steps.
Steps.shは、ジョブステップを実行するSlurmバッチスクリプトです。
Its main loop looks like this:
そのメインループは次のようになります。
for ((i = 1; i <= $num; i++))
do
# Run the $i step of my application
srun -l --mpi=pmi2 $PWD/star -t 10 > /dev/null
# After each step invoke the snonstop.sh script
# which will detect if any node has failed and
# will execute the actions specified by the user
# via the SMD_NONSTOP_FAILED variable
$PWD/nonstop.sh
if [ $? -ne 0 ]; then
exit 1
fi
echo "start: step $i `date`"
done
Let's run several tests, in all test we submit the batch jobs
as sbatch steps.sh.
いくつかのテストを実行してみましょう。すべてのテストで、バッチジョブをsbatchsteps.shとして送信します。
Note The batch job must use
the --no-kill option to prevent Slurm from terminating
the entire batch job upon one step failure.
注バッチジョブは、-no-killオプションを使用して、Slurmが1つのステップの失敗時にバッチジョブ全体を終了しないようにする必要があります。
- Set SMD_NONSTOP_FAILED="REPLACE"
- Setting num=2 to run only 2 steps.
- With no host failure the job will run to completion and the nonstop.sh
will print to its stdout the status of the nodes in the allocation.
ホストに障害が発生しない場合、ジョブは完了するまで実行され、nonstop.shは割り当て内のノードのステータスを標準出力に出力します。
start: step 0 Fri Mar 28 11:47:19 PDT 2014 is_failed: job 58 searching for FAILED hosts is_failed: job 58 has no FAILED nodes start: step 1 Fri Mar 28 11:47:55 PDT 2014 is_failed: job 58 searching for FAILED hosts is_failed: job 58 has no FAILED nodes
- Set SMD_NONSTOP_FAILED="REPLACE
- Setting num=10 to run 10 steps.
- As the job starts set one of the execution nodes down using the
scontrol command.
ジョブが開始したら、scontrolコマンドを使用して実行ノードの1つを下に設定します。
As soon as the running step finishes the nonstop.sh runs instructing the smd command to detect node failure and ask for replacement.
実行中のステップが終了するとすぐに、nonstop.shが実行され、smdコマンドにノードの障害を検出して交換を要求するように指示します。
The script stdout is:
スクリプトstdoutは次のとおりです。
is_failed: job 59 searching for FAILED hosts is_failed: job 59 has 1 FAILED nodes is_failed: job 59 FAILED node ercole cpu_count 1 _handle_fault: job 59 handle failed_hosts _try_replace: job 59 trying to replace 1 nodes _try_replace: job 59 node ercole replaced by prometeo _generate_node_file: job 59 all nodes replaced
- Examine the output of sinfo--format="%12P %.10n %.5T %.14C" command.
->sinfo PARTITION HOSTNAMES STATE CPUS(A/I/O/T) markab* dario mixed 1/15/0/16 markab* prometeo mixed 1/15/0/16 markab* spartaco idle 0/16/0/16 markab* ercole down 0/0/16/16
From the output we see the initial host ercole which went down was replaced by the host prometeo.
出力から、ダウンした最初のホストercoleがホストprometeoに置き換えられたことがわかります。
- Set SMD_NONSTOP_FAILED="REPLACE:TIME_LIMIT_DELAY=1:DROP:TIME_LIMIT_DROP=30"
- Modify steps.sh to run on all available nodes so when a node fails
there is no replacement available.
利用可能なすべてのノードで実行するようにsteps.shを変更して、ノードに障害が発生したときに利用可能な代替がないようにします。
- Upon the node failure the system will try for one minute to get a
replacement after that period of time will drop the node and extend the
job's runtime.
ノードに障害が発生すると、システムは1分間交換を試みます。その後、その期間がノードをドロップし、ジョブの実行時間を延長します。
This time the stdout is more verbose.
今回は、stdoutがより冗長になります。
is_failed: job 151 searching for FAILED hosts is_failed: job 151 has 1 FAILED nodes is_failed: job 151 FAILED node spartaco cpu_count 1 _handle_fault: job 151 handle failed_hosts _try_replace: job 151 trying to replace 1 nodes _try_replace: smd_replace_node() error job_id 151: Failed to replace the node _time_limit_extend: job 151 extending job time limit by 1 minutes _increase_job_runtime: job 151 run time limit extended by 1min successfully _try_replace: job 151 waited for 0 sec cnt 0 trying every 20 sec... _try_replace: job 151 trying to replace 1 nodes _try_replace: smd_replace_node() error job_id 151: Failed to replace the node _try_replace: job 151 waited for 20 sec cnt 1 trying every 20 sec..._try_replace: smd_replace_node() error job_id 151: Failed to replace the node _try_replace: job 151 waited for 40 sec cnt 2 trying every 20 sec... _try_replace: job 151 failed to replace down or failing nodes: spartaco _drop_nodes: job 151 node spartaco dropped all right _generate_node_file: job 151 all nodes replaced source the /tmp/smd_job_151_nodes.sh hostfile to get the new job environment _time_limit_extend: job 151 extending job time limit by 30 minutes _increase_job_runtime: job 151 run time limit extended by 30min successfully
As instructed the system tried to replace the failed node for a minute, then it drop the node and extended the runtime for 30 minutes.
指示に従って、システムは障害が発生したノードを1分間交換しようとした後、ノードを削除し、ランタイムを30分間延長しました。
The extended runtime must be within the system TimeLimitDrop configured in nonstop.conf.
拡張ランタイムは、nonstop.confで構成されたシステムTimeLimitDrop内にある必要があります。
The job step acquires the new environment from the hosts file
smd_job_$SLURM_JOB_ID_nodes.sh which is created by the smd
command in /tmp on the node where the batch script runs.
ジョブステップは、バッチスクリプトが実行されるノードの/ tmpにあるsmdコマンドによって作成されたホストファイルsmd_job_ $ SLURM_JOB_ID_nodes.shから新しい環境を取得します。
export SLURM_NODELIST=dario,prometeo export SLURM_JOB_NODELIST=dario,prometeo export SLURM_NNODES=2 export SLURM_JOB_NUM_NODES=2 export SLURM_JOB_CPUS_PER_NODE=2\(x2\) unset SLURM_TASKS_PER_NODE
This environment is sourced by the steps.sh script so the next job
steps will run using the new environment.
この環境はsteps.shスクリプトによって提供されるため、次のジョブステップは新しい環境を使用して実行されます。
Last modified 20 February 2014