Support for Multi-core/Multi-thread Architectures
Contents
- Definitions
- Overview of srun flags
- Motivation behind high-level srun flags
- Extensions to sinfo/squeue/scontrol
- Configuration settings in slurm.conf
Definitions
- BaseBoard
- Also called motherboard.
マザーボードとも呼ばれます。
- LDom
- Locality domain or NUMA domain.
ローカリティドメインまたはNUMAドメイン。
May be equivalent to BaseBoard or Socket.
BaseBoardまたはSocketと同等の場合があります。
- Socket/Core/Thread
- Figure 1 illustrates the notion of Socket, Core and Thread as it is defined
in Slurm's multi-core/multi-thread support documentation.
図1は、Slurmのマルチコア/マルチスレッドサポートドキュメントで定義されているソケット、コア、およびスレッドの概念を示しています。
- CPU
- Depending upon system configuration, this can be either a core or a thread.
システム構成に応じて、これはコアまたはスレッドのいずれかになります。
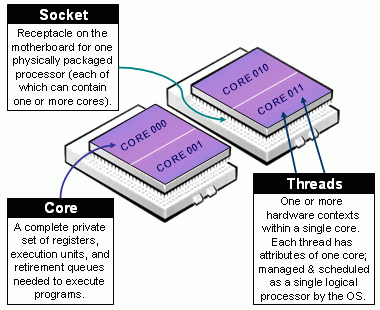
Figure 1: Definitions of Socket, Core, & Thread
- Affinity
- The state of being bound to a specific logical processor.
特定の論理プロセッサーにバインドされている状態。
- Affinity Mask
- A bitmask where indices correspond to logical processors.
インデックスが論理プロセッサに対応するビットマスク。
The least significant bit corresponds to the first logical processor number on the system, while the most significant bit corresponds to the last logical processor number on the system.
最下位ビットはシステムの最初の論理プロセッサ番号に対応し、最上位ビットはシステムの最後の論理プロセッサ番号に対応します。
A '1' in a given position indicates a process can run on the associated logical processor.
特定の位置にある「1」は、プロセスが関連する論理プロセッサで実行できることを示します。
- Fat Masks
- Affinity masks with more than 1 bit set
allowing a process to run on more than one logical processor.
1ビット以上が設定されたアフィニティマスクにより、プロセスを複数の論理プロセッサで実行できます。
Overview of srun flags
Many flags have been defined to allow users to
better take advantage of this architecture by
explicitly specifying the number of sockets, cores, and threads required
by their application.
アプリケーションに必要なソケット、コア、およびスレッドの数を明示的に指定することにより、ユーザーがこのアーキテクチャをより有効に活用できるように、多くのフラグが定義されています。
Table 1 summarizes these options.
表1は、これらのオプションをまとめたものです。
| Low-level (explicit binding) | |
| --cpu-bind=... | Explicit process affinity binding and control options 明示的なプロセスアフィニティバインディングと制御オプション |
| High-level (automatic mask generation) | |
| --sockets-per-node=S | Number of sockets in a node to dedicate to a job (minimum) ジョブ専用にするノード内のソケットの数(最小) |
| --cores-per-socket=C | Number of cores in a socket to dedicate to a job (minimum) ジョブ専用のソケット内のコアの数(最小) |
| --threads-per-core=T | Number of threads in a core to dedicate to a job (minimum) ジョブ専用のコア内のスレッド数(最小) |
| -B S[:C[:T]] | Combined shortcut option for --sockets-per-node, --cores-per_cpu, --threads-per_core --sockets-per-node、-cores-per_cpu、-threads-per_coreの組み合わせショートカットオプション |
| Task Distribution Options | |
| -m / --distribution | Distributions of: arbitrary | block | cyclic
| plane=x
| [block|cyclic]:[block|cyclic|fcyclic] の分布:任意| ブロック| サイクリック| 平面= x | [ブロック|サイクリック]:[ブロック|サイクリック| fサイクリック] |
| Memory as a consumable resource | |
| --mem=mem | amount of real memory per node required by the job. ジョブに必要なノードあたりの実メモリーの量。 |
| --mem-per-cpu=mem | amount of real memory per allocated CPU required by the job. ジョブに必要な、割り当てられたCPUあたりの実メモリーの量。 |
| Task invocation control | |
| --cpus-per-task=CPUs | number of CPUs required per task タスクごとに必要なCPUの数 | --ntasks-per-node=ntasks | number of tasks to invoke on each node 各ノードで呼び出すタスクの数 |
--ntasks-per-socket=ntasks | number of tasks to invoke on each socket 各ソケットで呼び出すタスクの数 |
--ntasks-per-core=ntasks | number of tasks to invoke on each core 各コアで呼び出すタスクの数 |
--overcommit | Permit more than one task per CPU CPUごとに複数のタスクを許可する |
| Application hints | |
| --hint=compute_bound | use all cores in each socket 各ソケットのすべてのコアを使用する | --hint=memory_bound | use only one core in each socket 各ソケットで1つのコアのみを使用します |
--hint=[no]multithread | [don't] use extra threads with in-core multi-threading [使用しない]コア内マルチスレッドで追加のスレッドを使用する |
| Resources reserved for system use | |
| --core-spec=cores | Count of cores to reserve for system use システムで使用するために予約するコアの数 | --thread-spec=threads | Count of threads to reserve for system use (future) システム使用のために予約するスレッドの数(将来) |
表1:マルチコア/マルチスレッド環境をサポートするためのsrunフラグ
It is important to note that many of these flags are only meaningful if the
processes have some affinity to specific CPUs and (optionally) memory.
これらのフラグの多くは、プロセスが特定のCPUおよび(オプションで)メモリにある程度の親和性を持っている場合にのみ意味があることに注意することが重要です。
Inconsistent options generally result in errors.
一貫性のないオプションは、通常、エラーになります。
Task affinity is configured using the TaskPlugin parameter in the slurm.conf file.
タスクアフィニティは、slurm.confファイルのTaskPluginパラメーターを使用して構成されます。
Several options exist for the TaskPlugin depending upon system architecture
and available software, any of them except "task/none" will bind tasks to CPUs.
TaskPluginには、システムアーキテクチャと使用可能なソフトウェアに応じていくつかのオプションがあり、「task / none」以外のオプションはタスクをCPUにバインドします。
See the "Task Launch" section if generating slurm.conf via
configurator.html.
configurator.htmlを介してslurm.confを生成する場合は、「タスクの起動」セクションを参照してください。
Low-level --cpu-bind=... - Explicit binding interface
The following srun flag provides a low-level core binding interface:
次のsrunフラグは、低レベルのコアバインディングインターフェイスを提供します。
--cpu-bind= Bind tasks to CPUs
q[uiet] quietly bind before task runs (default)
v[erbose] verbosely report binding before task runs
no[ne] don't bind tasks to CPUs (default)
rank bind by task rank
map_cpu:<list> specify a CPU ID binding for each task
where <list> is
<cpuid1>,<cpuid2>,...<cpuidN>
mask_cpu:<list> specify a CPU ID binding mask for each
task where <list> is
<mask1>,<mask2>,...<maskN>
rank_ldom bind task by rank to CPUs in a NUMA
locality domain
map_ldom:<list> specify a NUMA locality domain ID
for each task where <list> is
<ldom1>,<ldom2>,...<ldomN>
rank_ldom bind task by rank to CPUs in a NUMA
locality domain where <list> is
<ldom1>,<ldom2>,...<ldomN>
mask_ldom:<list> specify a NUMA locality domain ID mask
for each task where <list> is
<ldom1>,<ldom2>,...<ldomN>
boards auto-generated masks bind to boards
ldoms auto-generated masks bind to NUMA locality
domains
sockets auto-generated masks bind to sockets
cores auto-generated masks bind to cores
threads auto-generated masks bind to threads
help show this help message
The affinity can be either set to either a specific logical processor
(socket, core, threads) or at a coarser granularity than the lowest level
of logical processor (core or thread).
アフィニティーは、特定の論理プロセッサー(ソケット、コア、スレッド)に設定することも、最下位レベルの論理プロセッサー(コアまたはスレッド)よりも粗い粒度で設定することもできます。
In the later case the processes are allowed to utilize multiple processors
within a specific socket or core.
後者の場合、プロセスは特定のソケットまたはコア内で複数のプロセッサを利用できます。
Examples:
- srun -n 8 -N 4 --cpu-bind=mask_cpu:0x1,0x4 a.out
- srun -n 8 -N 4 --cpu-bind=mask_cpu:0x3,0xD a.out
See also 'srun --cpu-bind=help' and 'man srun'
High-level -B S[:C[:T]] - Automatic mask generation interface
We have updated the node
selection infrastructure with a mechanism that allows selection of logical
processors at a finer granularity.
より細かい粒度で論理プロセッサを選択できるメカニズムでノード選択インフラストラクチャを更新しました。
Users are able to request a specific number
of nodes, sockets, cores, and threads:
ユーザーは、特定の数のノード、ソケット、コア、およびスレッドを要求できます。
-B --extra-node-info=S[:C[:T]] Expands to:
--sockets-per-node=S number of sockets per node to allocate
--cores-per-socket=C number of cores per socket to allocate
--threads-per-core=T number of threads per core to allocate
each field can be 'min' or wildcard '*'
Total cpus requested = (Nodes) x (S x C x T)
Examples:
- srun -n 8 -N 4 -B 2:1 a.out
- srun -n 8 -N 4 -B 2 a.out
note: compare the above with the previous corresponding --cpu-bind=... examples
注:上記を前の対応する--cpu-bind = ...の例と比較してください
- srun -n 16 -N 4 a.out
- srun -n 16 -N 4 -B 2:2:1 a.out
- srun -n 16 -N 4 -B 2:2:1 a.out
or - srun -n 16 -N 4 --sockets-per-node=2 --cores-per-socket=2 --threads-per-core=1 a.out
- srun -n 16 -N 2-4 -B '1:*:1' a.out
- srun -n 16 -N 4-2 -B '2:*:1' a.out
- srun -n 16 -N 4-4 -B '1:1' a.out
Notes:
- Adding --cpu-bind=no to the command line will cause the processes
to not be bound the logical processors.
コマンドラインに--cpu-bind = noを追加すると、プロセスが論理プロセッサにバインドされなくなります。
- Adding --cpu-bind=verbose to the command line (or setting the
CPU_BIND environment variable to "verbose") will cause each task
to report the affinity mask in use
コマンドラインに--cpu-bind = verboseを追加する(またはCPU_BIND環境変数を「verbose」に設定する)と、各タスクは使用中のアフィニティマスクを報告します。
- Binding is on by default when -B is used.
-Bを使用すると、デフォルトでバインディングがオンになります。
The default binding on multi-core/multi-threaded systems is equivalent to the level of resource enumerated in the -B option.
マルチコア/マルチスレッドシステムのデフォルトのバインディングは、-Bオプションで列挙されたリソースのレベルと同等です。
See also 'srun --help' and 'man srun'
Task distribution options: Extensions to -m / --distribution
The -m / --distribution option for distributing processes across nodes
has been extended to also describe the distribution within the lowest level
of logical processors.
ノード間でプロセスを分散するための-m / --distributionオプションが拡張され、論理プロセッサの最下位レベル内での分散も記述できるようになりました。
Available distributions include:
利用可能なディストリビューションは次のとおりです。
arbitrary | block | cyclic | plane=x | [block|cyclic]:[block|cyclic|fcyclic]
The plane distribution (plane=x)
results in a block:cyclic distribution of blocksize equal to x.
平面分布(plane = x)は、xに等しいブロックサイズのブロック:巡回分布になります。
In the following we use "lowest level of logical processors"
to describe sockets, cores or threads depending of the architecture.
以下では、「最低レベルの論理プロセッサ」を使用して、アーキテクチャに応じてソケット、コア、またはスレッドを説明します。
The distribution divides
the cluster into planes (including a number of the lowest level of logical
processors on each node) and then schedule first within each plane and then
across planes.
ディストリビューションは、クラスターをプレーン(各ノード上の最下位レベルの論理プロセッサーの数を含む)に分割し、最初に各プレーン内で、次にプレーン間でスケジュールします。
For the two dimensional distributions ([block|cyclic]:[block|cyclic|fcyclic]),
the second distribution (after ":") allows users to specify a distribution
method for processes within a node and applies to the lowest level of logical
processors (sockets, core or thread depending on the architecture).
2次元分布([ブロック|サイクリック]:[ブロック|サイクリック| fcyclic])の場合、2番目の分布(「:」の後)を使用すると、ユーザーはノード内のプロセスの分散方法を指定でき、最下位レベルの論理に適用されます。プロセッサ(アーキテクチャに応じて、ソケット、コア、またはスレッド)。
When a task requires more than one CPU, the cyclic will allocate all
of those CPUs as a group (i.e. within the same socket if possible) while
fcyclic would distribute each of those CPU of the in a cyclic fashion
across sockets.
タスクに複数のCPUが必要な場合、サイクリックはそれらすべてのCPUをグループとして(つまり、可能であれば同じソケット内に)割り当てますが、fcyclicはそれらのCPUのそれぞれをサイクリック方式でソケット間で分散します。
The binding is enabled automatically when high level flags are used as long
as the task/affinity plug-in is enabled.
タスク/アフィニティプラグインが有効になっている限り、高レベルフラグが使用されると、バインディングは自動的に有効になります。
To disable binding at the job level
use --cpu-bind=no.
ジョブレベルでバインディングを無効にするには、-cpu-bind = noを使用します。
The distribution flags can be combined with the other switches:
配布フラグは、他のスイッチと組み合わせることができます。
- srun -n 16 -N 4 -B '2:*:1' -m block:cyclic --cpu-bind=socket a.out
- srun -n 16 -N 4 -B '2:*:1' -m plane=2 --cpu-bind=core a.out
- srun -n 16 -N 4 -B '2:*:1' -m plane=2 a.out
The default distribution on multi-core/multi-threaded systems is equivalent
to -m block:cyclic with --cpu-bind=thread.
マルチコア/マルチスレッドシステムでのデフォルトの配布は、-m block:cyclicと--cpu-bind = threadと同等です。
See also 'srun --help'
Memory as a Consumable Resource
The --mem flag specifies the maximum amount of memory in MB
needed by the job per node.
--memフラグは、ノードごとのジョブに必要なメモリの最大量をMB単位で指定します。
This flag is used to support the memory
as a consumable resource allocation strategy.
このフラグは、消費可能なリソース割り当て戦略としてメモリをサポートするために使用されます。
--mem=MB maximum amount of real memory per node
required by the job.
This flag allows the scheduler to co-allocate jobs on specific nodes
given that their added memory requirement do not exceed the total amount
of memory on the nodes.
このフラグを使用すると、追加されたメモリ要件がノードのメモリの合計量を超えない場合に、スケジューラが特定のノードにジョブを共同で割り当てることができます。
In order to use memory as a consumable resource, the select/cons_res
plugin must be first enabled in slurm.conf:
メモリを消費可能なリソースとして使用するには、slurm.confでselect / cons_resプラグインを最初に有効にする必要があります。
SelectType=select/cons_res # enable consumable resources SelectTypeParameters=CR_Memory # memory as a consumable resource
Using memory as a consumable resource is typically combined with
the CPU, Socket, or Core consumable resources using SelectTypeParameters
values of: CR_CPU_Memory, CR_Socket_Memory or CR_Core_Memory
消費可能なリソースとしてメモリを使用することは、通常、CR_CPU_Memory、CR_Socket_Memory、またはCR_Core_MemoryのSelectTypeParameters値を使用して、CPU、ソケット、またはコアの消費可能なリソースと組み合わされます。
See the "Resource Selection" section if generating slurm.conf
via configurator.html.
configurator.htmlを介してslurm.confを生成する場合は、「リソースの選択」セクションを参照してください。
See also 'srun --help' and 'man srun'
Task invocation as a function of logical processors
The --ntasks-per-{node,socket,core}=ntasks flags
allow the user to request that no more than ntasks
be invoked on each node, socket, or core.
--ntasks-per- {node、socket、core} = ntasksフラグを使用すると、ユーザーは、各ノード、ソケット、またはコアでntasksを超えないように要求できます。
This is similar to using --cpus-per-task=ncpus
but does not require knowledge of the actual number of cpus on
each node.
これは--cpus-per-task = ncpusの使用に似ていますが、各ノードの実際のCPU数を知る必要はありません。
In some cases, it is more convenient to be able to
request that no more than a specific number of ntasks be invoked
on each node, socket, or core.
場合によっては、各ノード、ソケット、またはコアで特定の数以下のntaskを呼び出すように要求できる方が便利です。
Examples of this include submitting
a hybrid MPI/OpenMP app where only one MPI "task/rank" should be
assigned to each node while allowing the OpenMP portion to utilize
all of the parallelism present in the node, or submitting a single
setup/cleanup/monitoring job to each node of a pre-existing
allocation as one step in a larger job script.
この例には、OpenMP部分がノードに存在するすべての並列処理を利用できるようにしながら各ノードに1つのMPI「タスク/ランク」のみを割り当てる必要があるハイブリッドMPI / OpenMPアプリの送信、または単一のセットアップ/クリーンアップ/の送信が含まれます。より大きなジョブスクリプトの1つのステップとして、既存の割り当ての各ノードへのジョブを監視します。
This can now be specified via the following flags:
これは、次のフラグを介して指定できるようになりました。
--ntasks-per-node=n number of tasks to invoke on each node --ntasks-per-socket=n number of tasks to invoke on each socket --ntasks-per-core=n number of tasks to invoke on each core
For example, given a cluster with nodes containing two sockets,
each containing two cores, the following commands illustrate the
behavior of these flags:
たとえば、ノードに2つのソケットがあり、それぞれに2つのコアが含まれているクラスターの場合、次のコマンドはこれらのフラグの動作を示しています。
% srun -n 4 hostname hydra12 hydra12 hydra12 hydra12 % srun -n 4 --ntasks-per-node=1 hostname hydra12 hydra13 hydra14 hydra15 % srun -n 4 --ntasks-per-node=2 hostname hydra12 hydra12 hydra13 hydra13 % srun -n 4 --ntasks-per-socket=1 hostname hydra12 hydra12 hydra13 hydra13 % srun -n 4 --ntasks-per-core=1 hostname hydra12 hydra12 hydra12 hydra12
See also 'srun --help' and 'man srun'
Application hints
Different applications will have various levels of resource
requirements.
アプリケーションが異なれば、さまざまなレベルのリソース要件があります。
Some applications tend to be computationally intensive
but require little to no inter-process communication.
一部のアプリケーションは計算量が多い傾向がありますが、プロセス間通信はほとんどまたはまったく必要ありません。
Some applications
will be memory bound, saturating the memory bandwidth of a processor
before exhausting the computational capabilities.
一部のアプリケーションはメモリにバインドされ、計算機能を使い果たす前にプロセッサのメモリ帯域幅を飽和させます。
Other applications
will be highly communication intensive causing processes to block
awaiting messages from other processes.
他のアプリケーションは通信集約型であるため、プロセスは他のプロセスからの待機中のメッセージをブロックします。
Applications with these
different properties tend to run well on a multi-core system given
the right mappings.
これらの異なるプロパティを持つアプリケーションは、適切なマッピングがあれば、マルチコアシステムで適切に実行される傾向があります。
For computationally intensive applications, all cores in a multi-core
system would normally be used.
計算量の多いアプリケーションの場合、通常、マルチコアシステムのすべてのコアが使用されます。
For memory bound applications, only
using a single core on each socket will result in the highest per
core memory bandwidth.
メモリバウンドアプリケーションの場合、各ソケットで単一のコアのみを使用すると、コアあたりのメモリ帯域幅が最大になります。
For communication intensive applications,
using in-core multi-threading (e.g. hyperthreading, SMT, or TMT)
may also improve performance.
通信を多用するアプリケーションの場合、コア内のマルチスレッド(ハイパースレッディング、SMT、TMTなど)を使用すると、パフォーマンスが向上する場合があります。
The following command line flags can be used to communicate these
types of application hints to the Slurm multi-core support:
次のコマンドラインフラグを使用して、これらのタイプのアプリケーションヒントをSlurmマルチコアサポートに伝達できます。
--hint= Bind tasks according to application hints
compute_bound use all cores in each socket
memory_bound use only one core in each socket
[no]multithread [don't] use extra threads with in-core multi-threading
help show this help message
For example, given a cluster with nodes containing two sockets,
each containing two cores, the following commands illustrate the
behavior of these flags.
たとえば、ノードに2つのソケットがあり、それぞれに2つのコアが含まれているクラスターの場合、次のコマンドはこれらのフラグの動作を示しています。
In the verbose --cpu-bind output, tasks
are described as 'hostname, task Global_ID Local_ID [PID]':
詳細な--cpu-bind出力では、タスクは「ホスト名、タスクGlobal_ID Local_ID [PID]」として記述されます。
% srun -n 4 --hint=compute_bound --cpu-bind=verbose sleep 1 cpu-bind=MASK - hydra12, task 0 0 [15425]: mask 0x1 set cpu-bind=MASK - hydra12, task 1 1 [15426]: mask 0x4 set cpu-bind=MASK - hydra12, task 2 2 [15427]: mask 0x2 set cpu-bind=MASK - hydra12, task 3 3 [15428]: mask 0x8 set % srun -n 4 --hint=memory_bound --cpu-bind=verbose sleep 1 cpu-bind=MASK - hydra12, task 0 0 [15550]: mask 0x1 set cpu-bind=MASK - hydra12, task 1 1 [15551]: mask 0x4 set cpu-bind=MASK - hydra13, task 2 0 [14974]: mask 0x1 set cpu-bind=MASK - hydra13, task 3 1 [14975]: mask 0x4 set
See also 'srun --hint=help' and 'man srun'
Motivation behind high-level srun flags
The motivation behind allowing users to use higher level srun
flags instead of --cpu-bind is that the later can be difficult to use.
ユーザーが--cpu-bindの代わりに高レベルのsrunフラグを使用できるようにする背後にある動機は、後者を使用するのが難しい場合があることです。
The
proposed high-level flags are easier to use than --cpu-bind because:
提案された高レベルフラグは、次の理由で--cpu-bindよりも使いやすいです。
- Affinity mask generation happens automatically when using the high-level flags.
アフィニティマスクの生成は、高レベルのフラグを使用すると自動的に行われます。 - The length and complexity of the --cpu-bind flag vs. the length
of the combination of -B and --distribution flags make the high-level
flags much easier to use.
--cpu-bindフラグの長さと複雑さ対-Bフラグと--distributionフラグの組み合わせの長さにより、高レベルのフラグがはるかに使いやすくなります。
Also as illustrated in the example below it is much simpler to specify
a different layout using the high-level flags since users do not have to
recalculate mask or CPU IDs.
また、以下の例に示すように、ユーザーはマスクまたはCPU IDを再計算する必要がないため、高レベルのフラグを使用して別のレイアウトを指定する方がはるかに簡単です。
This approach is much simpler than
rearranging the mask or map.
このアプローチは、マスクやマップを再配置するよりもはるかに簡単です。
Given a 32-process MPI job and a four dual-socket dual-core node
cluster, we want to use a block distribution across the four nodes and then a
cyclic distribution within the node across the physical processors.
32プロセスのMPIジョブと4つのデュアルソケットデュアルコアノードクラスターがある場合、4つのノード間でブロック分散を使用し、次に物理プロセッサ全体でノード内の循環分散を使用する必要があります。
We have had
several requests from users that they would like this distribution to be the
default distribution on multi-core clusters.
このディストリビューションをマルチコアクラスターのデフォルトのディストリビューションにすることを希望するユーザーからのリクエストがいくつかありました。
Below we show how to obtain the
wanted layout using 1) the high-level flags and 2) --cpubind
以下に、1)高レベルフラグと2)-cpubindを使用して必要なレイアウトを取得する方法を示します。
High-Level flags
Using Slurm's high-level flag, users can obtain the above layout with:
Slurmの高レベルフラグを使用すると、ユーザーは次の方法で上記のレイアウトを取得できます。
% mpirun -srun -n 32 -N 4 -B 4:2 --distribution=block:cyclic a.out
or% mpirun -srun -n 32 -N 4 -B 4:2 a.out
(since --distribution=block:cyclic is the default distribution)
The cores are shown as c0 and c1 and the processors are shown
as p0 through p3.
コアはc0およびc1として示され、プロセッサーはp0〜p3として示されます。
The resulting task IDs are:
結果のタスクIDは次のとおりです。
|
|
The computation and assignment of the task IDs is transparent
to the user.
タスクIDの計算と割り当ては、ユーザーに対して透過的です。
Users don't have to worry about the core numbering (Section
Pinning processes to cores) or any setting any CPU affinities.
ユーザーは、コアの番号付け(セクションのコアへのピン留めプロセス)やCPUアフィニティの設定について心配する必要はありません。
By default CPU affinity
will be set when using multi-core supporting flags.
マルチコアサポートフラグを使用する場合、デフォルトでCPUアフィニティが設定されます。
Low-level flag --cpu-bind
Using Slurm's --cpu-bind flag, users must compute the CPU IDs or
masks as well as make sure they understand the core numbering on their
system.
Slurmの--cpu-bindフラグを使用して、ユーザーはCPU IDまたはマスクを計算し、システムのコア番号を理解していることを確認する必要があります。
Another problem arises when core numbering is not the same on all
nodes.
コア番号がすべてのノードで同じでない場合、別の問題が発生します。
The --cpu-bind option only allows users to specify a single
mask for all the nodes.
--cpu-bindオプションでは、ユーザーはすべてのノードに単一のマスクを指定することしかできません。
Using Slurm high-level flags remove this limitation
since Slurm will correctly generate the appropriate masks for each requested nodes.
Slurmは、要求されたノードごとに適切なマスクを正しく生成するため、Slurmの高レベルフラグを使用すると、この制限がなくなります。
On a four dual-socket dual-core node cluster with core block numbering
The cores are shown as c0 and c1 and the processors are shown
as p0 through p3.
コアはc0およびc1として示され、プロセッサーはp0〜p3として示されます。
The CPU IDs within a node in the block numbering are:
(this information is available from the /proc/cpuinfo file on the system)
ブロック番号のノード内のCPUIDは次のとおりです(この情報は、システムの/ proc / cpuinfoファイルから入手できます)。
|
|
resulting in the following mapping for processor/cores
and task IDs which users need to calculate:
その結果、ユーザーが計算する必要のあるプロセッサー/コアとタスクIDのマッピングは次のようになります。
|
|
|
|
The above maps and task IDs can be translated into the
following mpirun command:
上記のマップとタスクIDは、次のmpirunコマンドに変換できます。
% mpirun -srun -n 32 -N 4 --cpu-bind=mask_cpu:1,4,10,40,2,8,20,80 a.out
or% mpirun -srun -n 32 -N 4 --cpu-bind=map_cpu:0,2,4,6,1,3,5,7 a.out
Same cluster but with its core numbered cyclic instead of block
On a system with cyclically numbered cores, the correct mask
argument to the mpirun/srun command looks like: (this will
achieve the same layout as the command above on a system with core block
numbering.)
周期的に番号が付けられたコアを持つシステムでは、mpirun / srunコマンドの正しいマスク引数は次のようになります(これにより、コアブロック番号が付けられたシステムでの上記のコマンドと同じレイアウトが実現されます)。
% mpirun -srun -n 32 -N 4 --cpu-bind=map_cpu:0,1,2,3,4,5,6,7 a.out
Block map_cpu on a system with cyclic core numbering
If users do not check their system's core numbering before specifying
the map_cpu list and thereby do not realize that the system has cyclic core
numbering instead of block numbering then they will not get the expected
layout.. For example, if they decide to re-use their mpirun command from above:
ユーザーがmap_cpuリストを指定する前にシステムのコア番号を確認せず、システムにブロック番号ではなく循環コア番号があることに気付かない場合、期待されるレイアウトが得られません。たとえば、再利用することにした場合上からのmpirunコマンド:
% mpirun -srun -n 32 -N 4 --cpu-bind=map_cpu:0,2,4,6,1,3,5,7 a.out
they get the following unintentional task ID layout:
次の意図しないタスクIDレイアウトを取得します。
|
|
since the processor IDs within a node in the cyclic numbering are:
サイクリックナンバリングのノード内のプロセッサIDは次のとおりです。
|
|
The important conclusion is that using the --cpu-bind flag is not
trivial and that it assumes that users are experts.
重要な結論は、-cpu-bindフラグの使用は簡単ではなく、ユーザーがエキスパートであると想定しているということです。
Extensions to sinfo/squeue/scontrol
Several extensions have also been made to the other Slurm utilities to
make working with multi-core/multi-threaded systems easier.
マルチコア/マルチスレッドシステムでの作業を容易にするために、他のSlurmユーティリティにもいくつかの拡張が行われました。
sinfo
The long version (-l) of the sinfo node listing (-N) has been
extended to display the sockets, cores, and threads present for each
node.
sinfoノードリスト(-N)の長いバージョン(-l)が拡張され、各ノードに存在するソケット、コア、およびスレッドが表示されます。
For example:
例えば:
% sinfo -N NODELIST NODES PARTITION STATE hydra[12-15] 4 parts* idle % sinfo -lN Thu Sep 14 17:47:13 2006 NODELIST NODES PARTITION STATE CPUS S:C:T MEMORY TMP_DISK WEIGHT FEATURES REASON hydra[12-15] 4 parts* idle 8+ 2+:4+:1+ 2007 41447 1 (null) none % sinfo -lNe Thu Sep 14 17:47:18 2006 NODELIST NODES PARTITION STATE CPUS S:C:T MEMORY TMP_DISK WEIGHT FEATURES REASON hydra[12-14] 3 parts* idle 8 2:4:1 2007 41447 1 (null) none hydra15 1 parts* idle 64 8:4:2 2007 41447 1 (null) none
For user specified output formats (-o/--format) and sorting (-S/--sort),
the following identifiers are available:
ユーザー指定の出力形式(-o / -format)および並べ替え(-S / -sort)の場合、次の識別子を使用できます。
%X Number of sockets per node
%Y Number of cores per socket
%Z Number of threads per core
%z Extended processor information: number of
sockets, core, threads (S:C:T) per node
For example:
% sinfo -o '%9P %4c %8z %8X %8Y %8Z' PARTITION CPUS S:C:T SOCKETS CORES THREADS parts* 4 2:2:1 2 2 1
See also 'sinfo --help' and 'man sinfo'
squeue
For user specified output formats (-o/--format) and sorting (-S/--sort),
the following identifiers are available:
ユーザー指定の出力形式(-o / -format)および並べ替え(-S / -sort)の場合、次の識別子を使用できます。
%m Size of memory (in MB) requested by the job
%H Number of requested sockets per node
%I Number of requested cores per socket
%J Number of requested threads per core
%z Extended processor information: number of requested
sockets, cores, threads (S:C:T) per node
Below is an example squeue output after running 7 copies of:
以下は、7つのコピーを実行した後のスキュー出力の例です。
- % srun -n 4 -B 2:2:1 --mem=1024 sleep 100 &
% squeue -o '%.5i %.2t %.4M %.5D %7H %6I %7J %6z %R' JOBID ST TIME NODES SOCKETS CORES THREADS S:C:T NODELIST(REASON) 17 PD 0:00 1 2 2 1 2:2:1 (Resources) 18 PD 0:00 1 2 2 1 2:2:1 (Resources) 19 PD 0:00 1 2 2 1 2:2:1 (Resources) 13 R 1:27 1 2 2 1 2:2:1 hydra12 14 R 1:26 1 2 2 1 2:2:1 hydra13 15 R 1:26 1 2 2 1 2:2:1 hydra14 16 R 1:26 1 2 2 1 2:2:1 hydra15
The squeue command can also display the memory size of jobs, for example:
squeueコマンドは、ジョブのメモリサイズを表示することもできます。次に例を示します。
% sbatch --mem=123 tmp Submitted batch job 24 $ squeue -o "%.5i %.2t %.4M %.5D %m" JOBID ST TIME NODES MIN_MEMORY 24 R 0:05 1 123
See also 'squeue --help' and 'man squeue'
scontrol
The following job settings can be adjusted using scontrol:
次のジョブ設定は、scontrolを使用して調整できます。
Requested Allocation: ReqSockets=<count> Set the job's count of required sockets ReqCores=<count> Set the job's count of required cores ReqThreads=<count> Set the job's count of required threads
For example:
# scontrol update JobID=17 ReqThreads=2 # scontrol update JobID=18 ReqCores=4 # scontrol update JobID=19 ReqSockets=8 % squeue -o '%.5i %.2t %.4M %.5D %9c %7H %6I %8J' JOBID ST TIME NODES MIN_PROCS SOCKETS CORES THREADS 17 PD 0:00 1 1 4 2 1 18 PD 0:00 1 1 8 4 2 19 PD 0:00 1 1 4 2 1 13 R 1:35 1 0 0 0 0 14 R 1:34 1 0 0 0 0 15 R 1:34 1 0 0 0 0 16 R 1:34 1 0 0 0 0
The 'scontrol show job' command can be used to display
the number of allocated CPUs per node as well as the socket, cores,
and threads specified in the request and constraints.
'scontrol show job'コマンドを使用して、ノードごとに割り当てられたCPUの数、および要求と制約で指定されたソケット、コア、スレッドを表示できます。
% srun -N 2 -B 2:1 sleep 100 & % scontrol show job 20 JobId=20 UserId=(30352) GroupId=users(1051) Name=sleep Priority=4294901749 Partition=parts BatchFlag=0 AllocNode:Sid=hydra16:3892 TimeLimit=UNLIMITED JobState=RUNNING StartTime=09/25-17:17:30 EndTime=NONE NodeList=hydra[12-14] NodeListIndices=0,2,-1 AllocCPUs=1,2,1 NumCPUs=4 ReqNodes=2 ReqS:C:T=2:1:* OverSubscribe=0 Contiguous=0 CPUs/task=0 MinCPUs=0 MinMemory=0 MinTmpDisk=0 Features=(null) Dependency=0 Account=(null) Reason=None Network=(null) ReqNodeList=(null) ReqNodeListIndices=-1 ExcNodeList=(null) ExcNodeListIndices=-1 SubmitTime=09/25-17:17:30 SuspendTime=None PreSusTime=0
See also 'scontrol --help' and 'man scontrol'
Configuration settings in slurm.conf
Several slurm.conf settings are available to control the multi-core
features described above.
上記のマルチコア機能を制御するために、いくつかのslurm.conf設定を使用できます。
In addition to the description below, also see the "Task Launch" and
"Resource Selection" sections if generating slurm.conf
via configurator.html.
以下の説明に加えて、configurator.htmlを介してslurm.confを生成する場合は、「タスクの起動」セクションと「リソースの選択」セクションも参照してください。
As previously mentioned, in order for the affinity to be set, the
task/affinity plugin must be first enabled in slurm.conf:
前述のように、アフィニティを設定するには、最初にタスク/アフィニティプラグインをslurm.confで有効にする必要があります。
TaskPlugin=task/affinity # enable task affinity
This setting is part of the task launch specific parameters:
この設定は、タスク起動固有のパラメーターの一部です。
# o Define task launch specific parameters # # "TaskProlog" : Define a program to be executed as the user before each # task begins execution. # "TaskEpilog" : Define a program to be executed as the user after each # task terminates. # "TaskPlugin" : Define a task launch plugin. This may be used to # provide resource management within a node (e.g. pinning # tasks to specific processors). Permissible values are: # "task/affinity" : CPU affinity support # "task/cgroup" : bind tasks to resources using Linux cgroup # "task/none" : no task launch actions, the default # # Example: # # TaskProlog=/usr/local/slurm/etc/task_prolog # default is none # TaskEpilog=/usr/local/slurm/etc/task_epilog # default is none # TaskPlugin=task/affinity # default is task/none
Declare the node hardware configuration in slurm.conf:
slurm.confでノードハードウェア構成を宣言します。
NodeName=dualcore[01-16] CoresPerSocket=2 ThreadsPerCore=1
For a more complete description of the various node configuration options
see the slurm.conf man page.
さまざまなノード構成オプションの詳細については、slurm.confのマニュアルページを参照してください。
Last modified 9 October 2019